
寒假学习笔记
Daily Hacking
1.11
- 看了一集脱壳王,主要讲了编译AOSP8.0的一些注意点
- k8s: Pod产生的原因是因为容器之间的超亲密关系,解决成组调度的问题,以及容器设计模式这一重要概念,为了避免容器之间的依赖关系,使用Infra容器创建namespace.
- 在使用
minikube进行实验的过程中,尽管使用minikube启动了一个pod,但是使用docker ps -a查看发现只有一个kicbase容器在运行,这是docker in docker吗,docker in docker的namespace之间的层级关系又是什么样子的呢,之前文章中有提到会有隐患,会有什么样的隐患呢

- 每日一道LeetCode题目
1.12
- 整了一下论文评阅书,送明审
- LeetCode每日一题
- 继续学习k8s,主要学
projected volume,里面的serect(加密信息,保存在etcd中)、configmap(配置信息,通常为k-v对)、downloader api(用户获取pod相关信息,但是只能获取pre-set的),使用kubectl describe pod指令可以获取到Pod的相关信息,包括container等,events也是在这里查
1 | ➜ KubeMiniTest kubectl describe pod nginx |
service account证书存放地点:

使用liveness code代替容器的status来判断当前pod的运行状态是最重要的手段之一
1 | Type Reason Age From Message |
- PodPreset用于批量化的对pod的配置文件添加一些预设置好的字段,比如说通过match lable去给某种指定功能的pod添加环境变量
1.13
- k8s一讲:今天主要学的是容器编排,这一功能是由k8s的controller实现的,对应目录为
kubernetes/pkg/controller/,k8s的控制循环的模式为控制循环,实际状态调整为期望状态,deployment也会创建容器,中途出现了
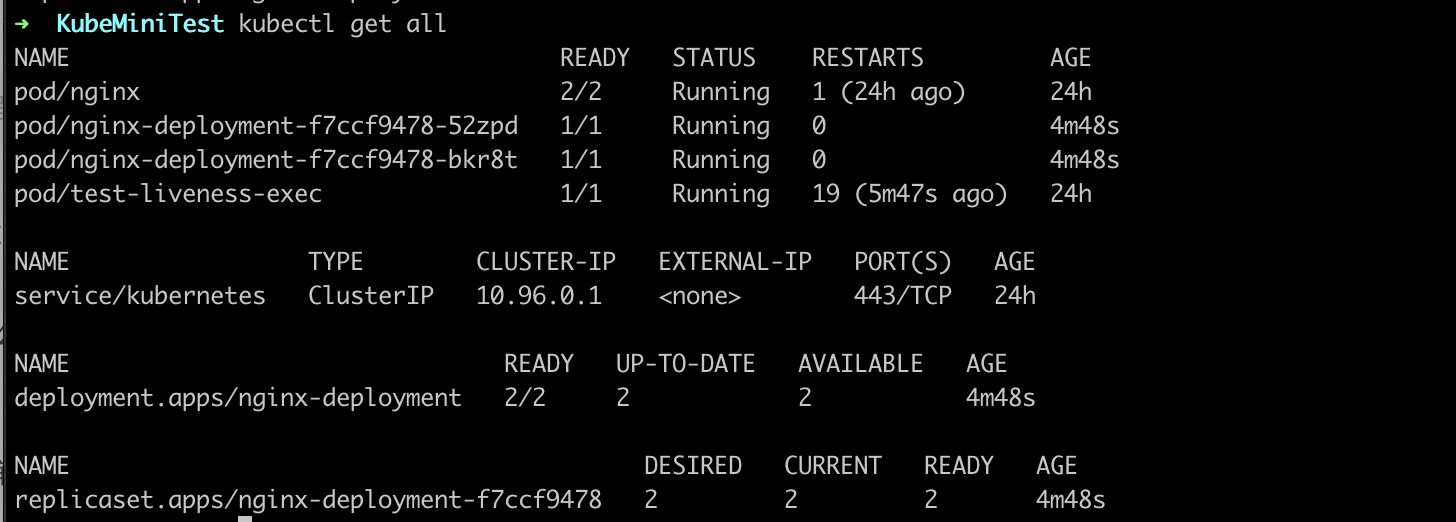
Deployment 创建 ReplicaSet, ReplicaSet创建pod, 提供了水平扩容功能,每次进行delpoyment的更新都会创建新的replica对象,replica对象会带有hash,如果不想创建过多replica对象,那就先pause,修改后再resume,spec.revisionHistoryLimit可以控制历史replicaSet的数量
leetcode今天和昨天的每日一题
1.15
凌晨脑子有点乱,理解了好久才彻底弄懂了最大公约数那题,首先用hashmap对数组里的数字进行存在性处理,这题主要巧妙在不暴力遍历全部子序列,而是从公约数开始便利,公约数一定是1到max,然后对筛选出合法的,这里由于并不是要找到某个具体的值,所以不能用二分查找,查找的依据是,找到这个数所有的倍数在数组中命中的,以3为例,数组中可能命中6,18,这个时候gcd是6不是3,因此需要进行判断,初始gcd设置为0,第一次命中后设置为命中后的值,如果不是0,则更新为gcd(j,tmpGcd),判断是否等于遍历的那个,一旦有一个gcd等于当前这个,说明存在子序列里,立马break,继续下一个数,以4,6,10为例,2的时候,找到4了就立马退出,3找到6了立马退出,给我的启发是:一个纬度的遍历复杂度过高时,可以考虑从另一个维度遍历
今天每日一题是一个easy,轻松秒掉
今日k8s: StatefulSet,主要用于解决有状态的容器编排关系,主要有两种关系,拓扑关系(主从之类的,这部分可以在yaml中设置InitContainer实现?),存储关系(例如分布式数据库,需要保证掉线的结点重新上线后存储的一致性), 有两种方法访问到Pod,一种是通过VIP,直接在service的yaml文件中定义代理的虚拟IP,另一种则是通过DNS,不定义clusterIP,通过唯一身份标识去访问Pod,
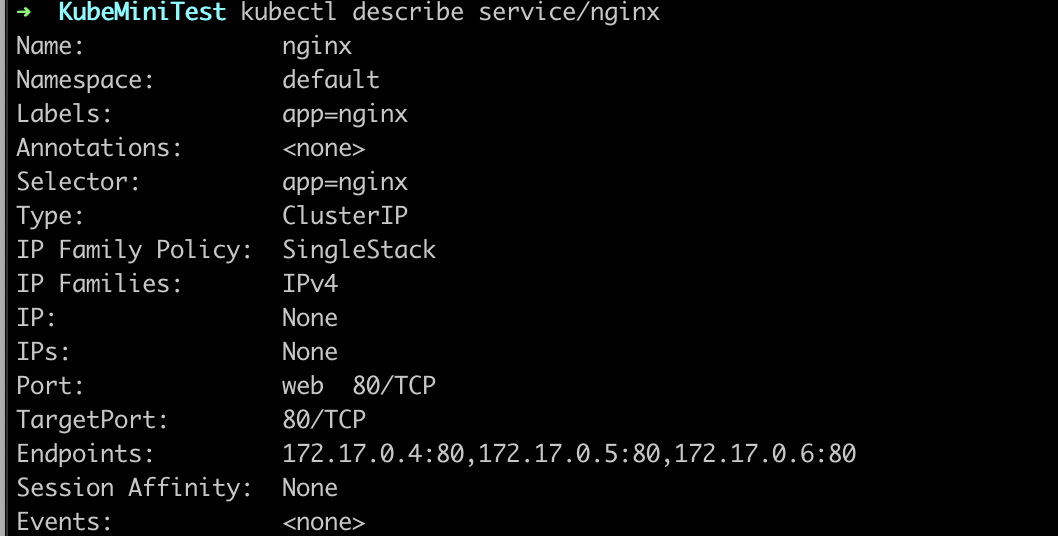
- 查询DNS访问,statefulSet用于严格保证pod按照一定的顺序启动,这里有个问题,比如说 statefulSet可以用于解决主从之类的拓扑关系,可是他只能保证pod的启动顺序,这里怎么保证是主节点先启动,而不是从节点先启动?难道说是先有启动顺序,然后再去编号不同的Pod里执行脚本,完成主从的配置嘛?归根到底也就是一个现有顺序还是先有主从这一拓扑关系的问题(因为我之前用docker手动配置过mysql的主从集群,两个容器配置差别很大,假设用replica这个参数启动的容器肯定是一模一样的,这种情况是不是只能等启动一样的镜像之后再去配置主从关系)(已解决,查了下用k8s部署主从集群的情况,用configmap存储主从的配置信息,用initContainer确定启动顺序,用statefulSet动态保障启动顺序)
1 | - bash |
1.16
- LeetCode每日一题,今天是一道双指针,还行
- 想了下之前理解的有问题,InitContainer是用来保证一个Pod内部容器启动顺序的字段,StatefulSet则是作用于Pod的编排中,两者并不在一个层级,之前理解的有问题
敏捷开发:当前最流行的敏捷框架 Scrum,学习了当前互联网产品的开发流程,学习了在编码开发过程中需要遵循的规范,编码规范、接口设计规范、版本控制规范、日志规范等,这是十年前流行的Git Flow工作流,但是随着敏捷开发的流行现在使用更多的是Github Flow工作流,仓库管理者创建仓库,开发者fork并且提pr,最后合并分支,其中commit信息以及pr信息都需要合理的规范
Master 分支:作为唯一一个正式对外发布的分支,是所有分支里最稳定的。 * Develop 分支:是根据 Master 分支创建出来的。Develop 分支作为一种集成分支 (Integration Branch),专门用来集成已经开发完的各种特性。
- Feature 分支:根据 Develop 分支创建出来。Gitflow 工作流里的每个新特性都有自己的 Feature 分支。当特性开发结束以后,这些分支上的工作会被合并到 Develop 分支。
- Release 分支:当积累了足够多的已完成特性,或者预定的系统发布周期临近的时候,我们就会从 Develop 分支创建出一个 Release 分支,专门做和当前版本发布有关的工作。Release 分支一旦创建,就不允许再有新的特性被加入到这个分支了,只有修复 Bug 或者编辑文档之类的工作才能够进入该分支。Release 分支上的内容最终会被合并到 Master 分支。
- Hotfix 分支:直接根据 Master 分支创建,目的是给运行在生产环境中的系统快速提供补丁。当 Hotfix 分支上的工作完成以后,可以合并到 Master 分支、Develop 分支以及当前的 Release 分支。如果有版本的更新,也可以为 Master 分支打上相应的 Tag。
反爬虫手段: IP 校验、HTTP Header 校验、验证码、登陆限制、CSS 数据伪装、sign 参数签名等
看了golang的高并发网络编程,也就是协程+IO多路复用,epoll的技术忘的差不多了,从底层重新补一下,sokcet其实代表的是一个连接,CPU收到来自于该连接的数据包之后则会讲数据包的端口号拷贝到内存中对应socket的缓冲区中,这个过程中会有一次中断(此时数据仍然是在内核态的,用户进程使用还需要进行一次复制,而ebpf这种技术的初衷,正是为了减少拷贝无效数据包而对数据包进行伯克利过滤)
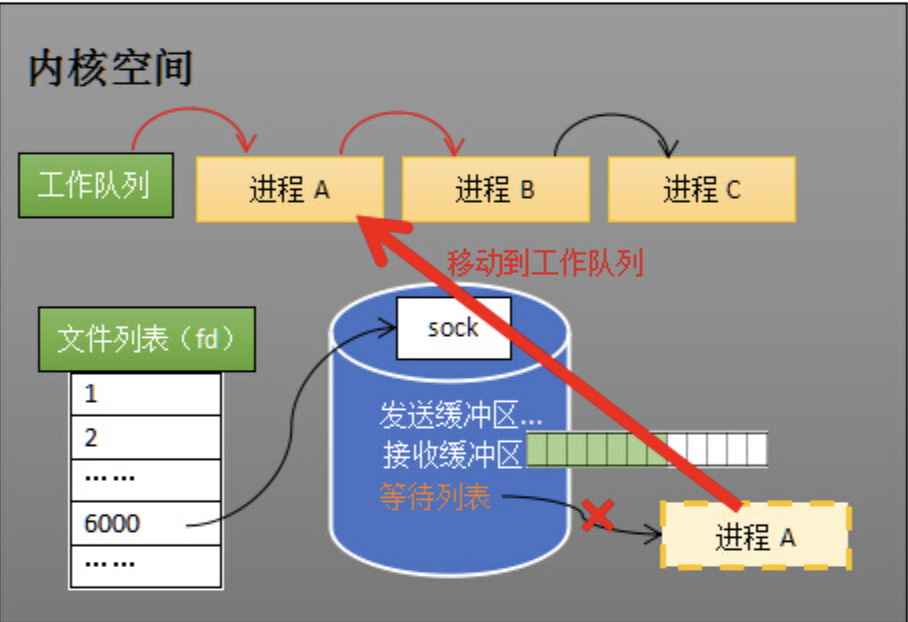
- select是最早用于监视多个socket是否有数据返回的方法,假设一个程序创建了大量连接,则内核需要监视多个socket判断哪个socket来了数据,缺点明显:1 要把所有的socket传给内核 2 两次遍历,每次调用select都需要将进程加入到所有监视socket的等待队列,每次唤醒都需要从每个队列中移除。这里涉及了两次遍历,epoll的设计初衷就是为了减少遍历的次数
- epoll技术等于说将唤醒进程与socket就绪的进程解藕,核心数据结构有等待队列、rbr、rdlist(就绪队列),通过rdlist可以让被唤醒的进程快速知道哪个socket就绪了,减少了一次遍历,rbr用于维护当前监视的socket
- 今日k8s: statefulSet的rollUpdate顺序是按照编号的相反顺序,如果想要实现金丝雀发布(批量发布),可以设置partitin字段,DameonSet即守护进程,这个会确保每个Node上都有且只有一个被DameonSet管理的Pod,并且可以在整个集群启动之前启动(得益于Toleration功能,即无视被标有污点的Node)
- 至此,通过上面这些内容,你应该能够明白,DaemonSet 其实是一个非常简单的控制器。在它的控制循环中,只需要遍历所有节点,然后根据节点上是否有被管理 Pod 的情况,来决定是否要创建或者删除一个 Pod。只不过,在创建每个 Pod 的时候,DaemonSet 会自动给这个 Pod 加上一个 nodeAffinity,从而保证这个 Pod 只会在指定节点上启动。同时,它还会自动给这个 Pod 加上一个 Toleration,从而忽略节点的 unschedulable“污点”。
- 关于DaemonSet的版本管理,使用的是ControllerRevision,但是Deployment由于有ReplicaSet这一中间层的缘故,并没有使用这个进行版本管理
1.17
- Leetcode每日一题,两数之和变种题轻松秒
1.27
- leetcode每日一题
- 在k8s中任务分为两种,Long Running Service(LRS)与Job,Job是指运行后退出的工作,其次,Job Controller 在控制循环中进行的调谐(Reconcile)操作,是根据实际在 Running 状态 Pod 的数目、已经成功退出的 Pod 的数目,以及 parallelism、completions 参数的值共同计算出在这个周期里,应该创建或者删除的 Pod 数目,然后调用 Kubernetes API 来执行这个操作。
三种常用使用模式,一种是通过模版+外部控制器修改,编辑文件后创建job,这种比较常用,但是parallelism和completions应该设置为1,并行度应该由外部控制器决定,比如说多创建几次job?管理器多个job的话可以通过统一的label
普通的job控制器只可以控制job之前不存在状态的情况,如果做批量计算(比如说下一批的计算需要用到上一批计算的结果),这种情况需要使用operaotr+job
cronjob就是定时任务,通过cronjob可以指定一些特殊情况,比如说旧的没运行完成新的又要创建这种,cronjob控制器用于控制job对象,使用对象控制另一种对象是k8s的精髓
docker既可以使用宿主机的网络(类似于虚拟机的NAT),也可以创建自己的network namespace,拥有自己的ip和端口,docker容器之间的相互通信是借由于创建在宿主机上的虚拟网桥docker0实现的,容器通过veth虚拟出的两张网卡接入网桥,一个veth在docker中,一个在宿主机里
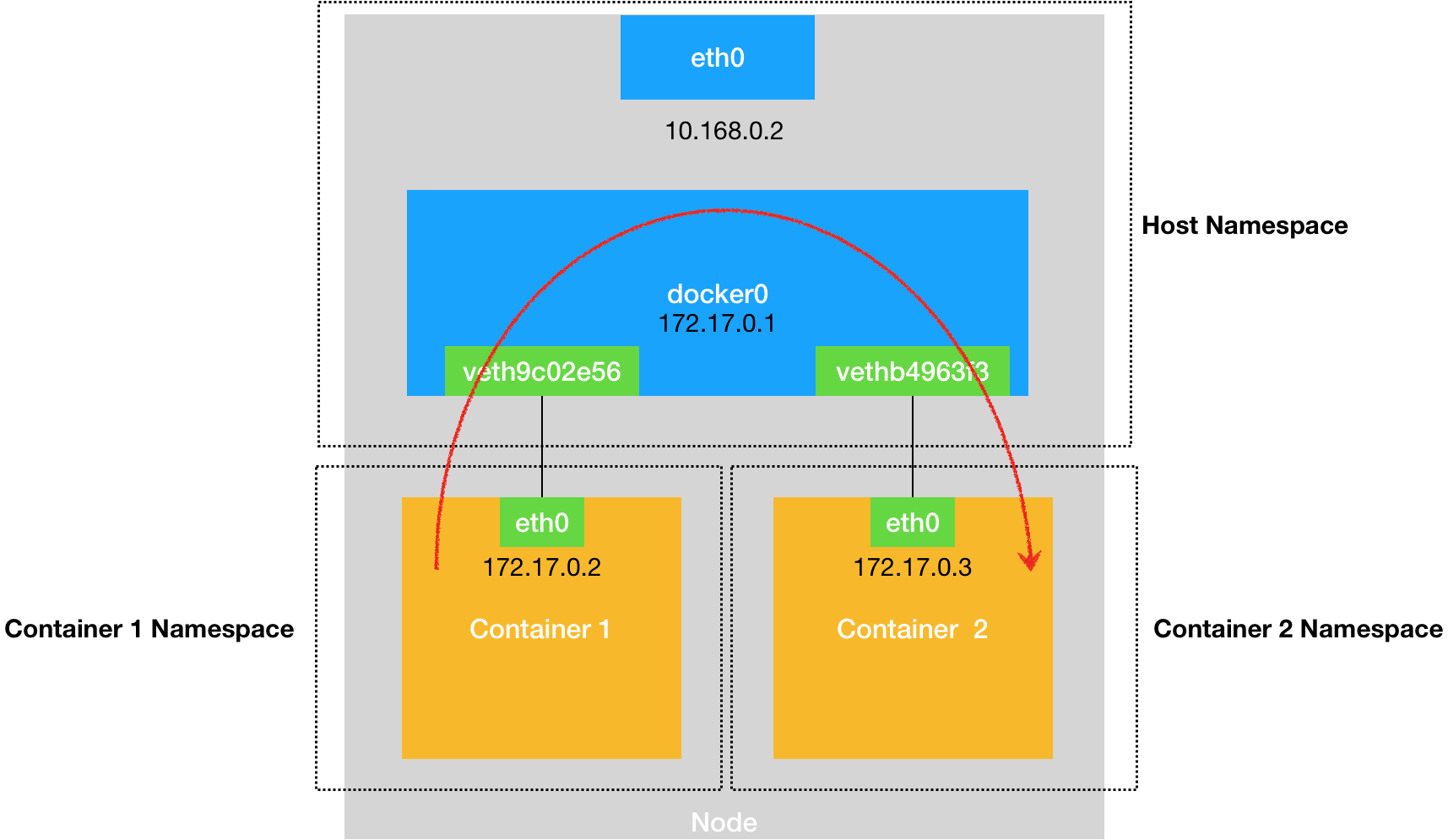
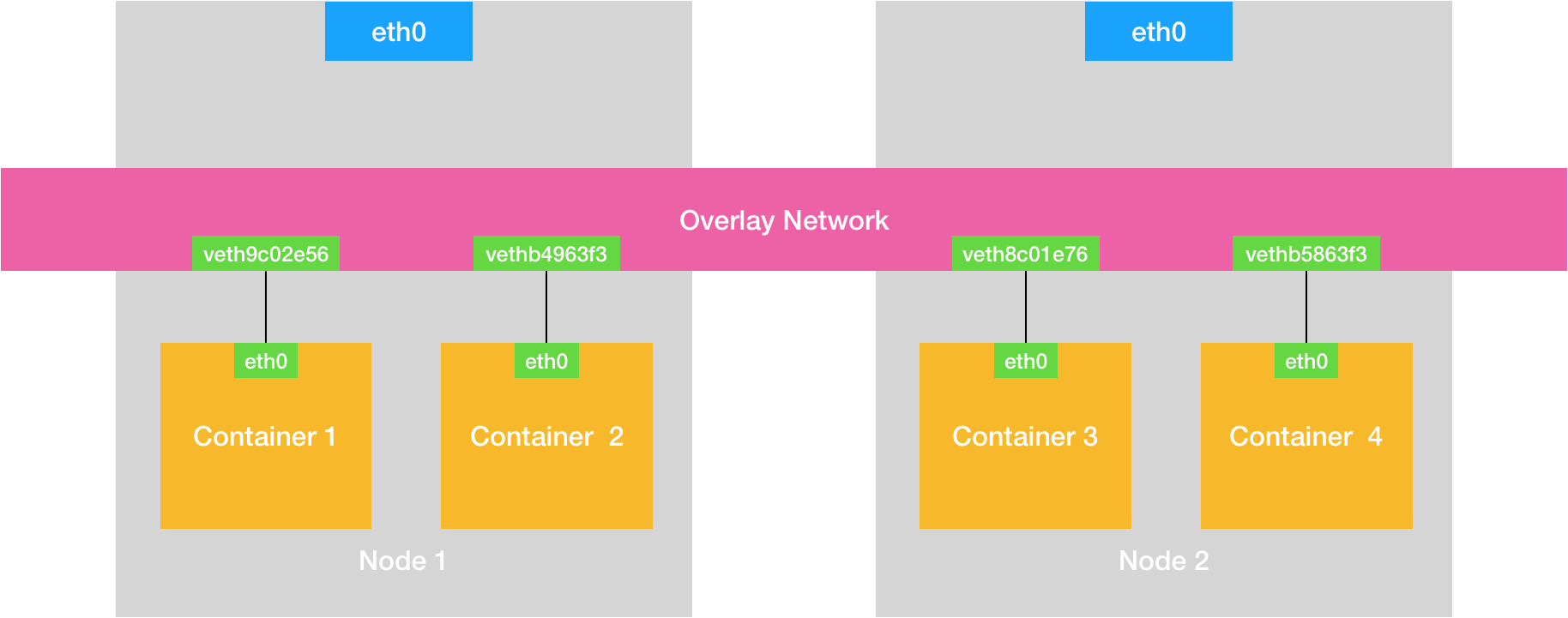
- 容器的跨主通信万变不离其宗,还是创建一个公用的虚拟网桥取代docker0
1.30
Leetcode每日一题
跨主机通信的项目以flannel为例,是通过创建tunnel在内核捕获到网络数据包之后发送至应用态的flannel进程,最后在应用层转发至flannel子网中对应的node上,这个子网和node的对应关系保存在etcd中,udp模式通过监听8825端口实现数据包的传递,性能差的原因是内核与应用之间的数据包拷贝次数过多(不得不再cue一下ebpf),因此在性能优化时,尽量把逻辑放在内核
不使用udp模式使用vxlan模式的好处是网络数据包拷贝次数减少,用的是vtep虚拟网络隧道,vtep的用途和flanneld类似,只不过他在内核里处理数据包,处在二层网络,包装的是frame,其中对方vtep设备的mac地址不通过arp学习得到,而是一个node加入网络后直接由插件添加至路由规则中,所以说其实就是除了vtep层的包是要特殊处理的(不知道目标vtep的ip和mac),这部分用ebpf实现就行,找到了一个想法和我一样的:https://zhuanlan.zhihu.com/p/565254116

1.31
- 弄了好久ebpf环境,记录一下:
- wget -c https://dl.google.com/go/go1.19.2.linux-amd64.tar.gz -O - | sudo tar -xz -C /usr/local
- vim /etc/profile
- export PATH=$PATH:/usr/local/go/bin
- export GO111MODULE=on
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package main
import (
"fmt"
bpf "github.com/iovisor/gobpf/bcc"
"os"
)
import "C"
const source string = `
int kprobe__do_sys_open(void *ctx)
{
bpf_trace_printk("Hello, World!\\n");
return 0;
}
`
func main() {
m := bpf.NewModule(source, []string{})
defer m.Close()
kp, err := m.LoadKprobe("kprobe__do_sys_open")
if err != nil {
fmt.Printf("Failed to load kprobe count: %s\n", err)
os.Exit(1)
}
err = m.AttachKprobe("do_sys_open", kp, -1)
if err != nil {
fmt.Printf("Failed to attach kprobe to strlen: %s\n", err)
os.Exit(1)
}
for {
fmt.Println("waiting...")
time.Sleep(time.Second * 10)
}
}
2.1
- k8s启动一个pod后第一步就是为infra containner配置网络栈,CNI插件本质上是一些二进制文件,这些二进制文件只需要负责配置网络,并且返回给dockershim IP地址就行,这个 ADD 和 DEL 操作,就是 CNI 插件唯一需要实现的两个方法。
- kubelet 创建 Pod ->创建 Infra 容器。主要是由(CRI)dockershim 调用 Docker API 创建并启动 Infra 容器-> SetUpPod方法。方法的作用是:1.为 CNI 插件准备参数,2.然后调用 CNI 插件为 Infra 容器配置网络。
- 1.所需参数->实现ADD/DEL方法->CNI插件(flannel插件)实现。:
- 1.1参数一:由 dockershim 设置的一组 CNI 环境变量,ADD/DEL方法参数。
- 1.2参数二:是 dockershim 从 CNI “配置文件”里加载到的、默认插件的配置信息;由flannel网络方案本身安装时生成。
- 2.调用 CNI 插件:引:”dockershim 对 Flannel CNI 插件的调用,其实就是走了个过场。Flannel CNI 插件唯一需要做的,就是对 dockershim 传来的 Network Configuration (CNI配置文件)进行补充。”接下来,Flannel CNI 插件->调用 CNI bridge 插件(参数一:“CNI环境变量/ADD”, 参数二:”Network Confiuration/Delegate”),–>“代表”Flannel,将容器加入CNI网络(cni0网桥)
- k8s还有一种三层网络模式,以flannel的host-gw模式为例:host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
- ebpf程序首先使用llvm编译器把程序编译成字节码,然后字节码作为bpf系统调用的参数加载bpf到内核(这一部为bpf指令),加载到内核之后bpf JIT则会编译成真正执行的机器指令执行,查看bpf字节码:
bpftool prog dump xlated id xx,查看jit编译后的机器指令则把xlated改成jited,内核同时创建一个bpf的对象,然后进行验证操作,判断是否安全,接着查询 kprobe 类型的事件编号,用这个编号创建对应类型的事件之后,使用ioctl把ebpf绑定到事件上
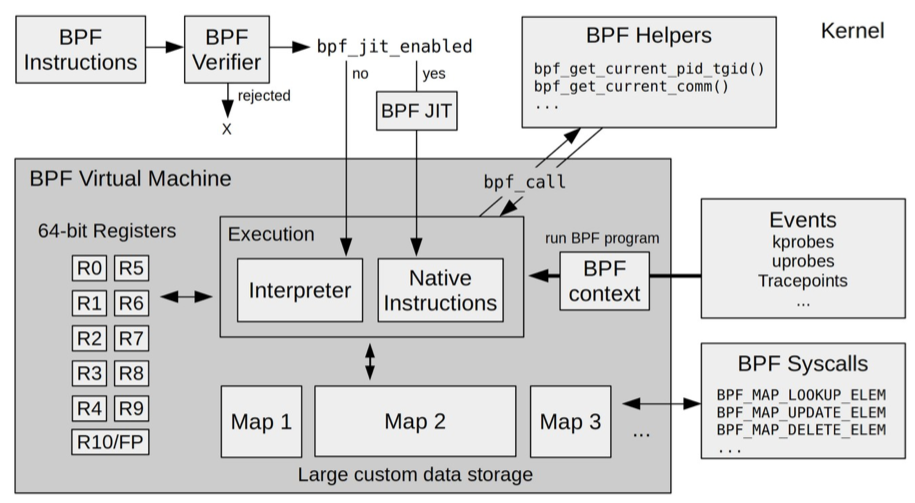
- ebpf程序之间的通信可以通过共享ebpf map的方式实现,ebpf map只能通过系统调用创建,返回的是一个文件句柄,通过共享文件句柄可以实现共享内存
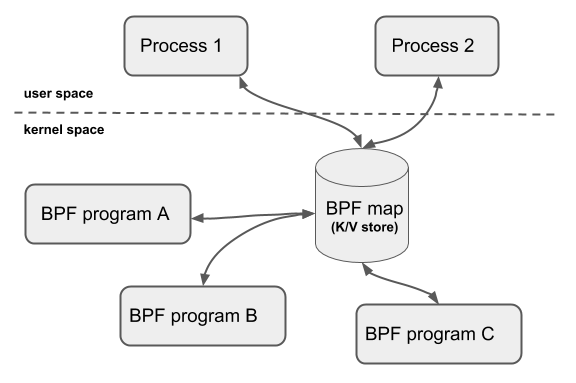
2.2
- 光顾着打游戏,就做了一题leetcode,两次bfs,不过还是做出来了,好多东西都忘记了,如果想要避免图中出现环的情况,需要设置visited数组,这题比较特殊,从相同颜色的路线进出才会形成环
2.3
LeetCode一题,碰到游戏取胜类的题目一般要优先考虑获胜策略,有了明确的策略会将问题简化很多
省考没进面,操!!!!! 60 + 58
- 看雪看了下,看到了一个用frida进行类似于fart的脱壳的文章,通过frida首先hook执行选项使得程序走switch解释模式(因为art也是有jit的,如果不走switch模式可能没法跟踪到smali指令,而是跟踪到jit好的机器指令),hook shadow_frame.GetThisObject这个函数可跟踪执行具体的每一条smali指令,其中指令中的class id与method id需要从整体dump的dex中索引,这应该就是没有主动调用的fart版本
- epbf的类型第一类是跟踪,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么。第二类是网络,即对网络数据包进行过滤和处理(xdp与TC),以便了解和控制网络数据包的收发过程。第三类是除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等。
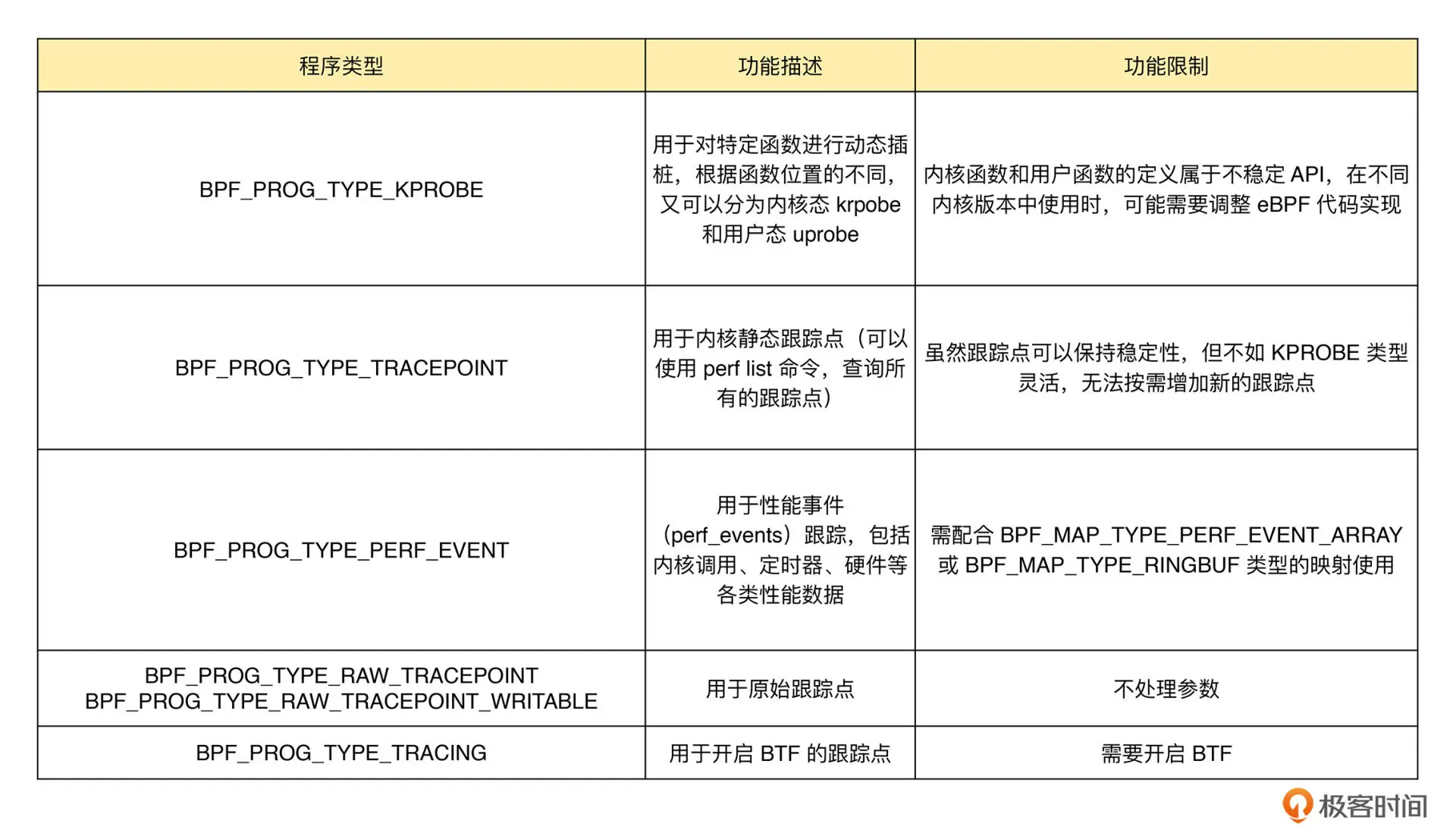
- Cilium值得分析
2.7
- LeetCode 每日一题
- 通过
-l命令可以找到linux内核中所有的挂载点,-lv可以查看挂载点的函数签名
- 既可以通过内核调试信息和 perf 来查询内核函数、跟踪点以及性能事件的列表,也可以使用 bpftrace 工具来查询。
2.11
- LeetCode每日一题
- 下午做了一下言语刷题,晚上看了下课程
- 50题电网领航1000题,复习了冯诺依曼、原、补、移码、IEEE754等知识
- 处于恢复期,没正式进入状态
2.12
- LeetCode 每日一题,曼哈顿距离
- 电网复习 100题,复习了OSI七层网络模型与TCP\IP四层网络模型,又看了下TCP协议的滑动窗口与三次握手,四次挥手,温习了常用协议所在的网络分层以及端口号
- ebpf学习:开发、加载ebpf程序可以借助bcc,bcc会帮你完成编译、加载、挂载等步骤,但是在没有bcc的情况下就需要使用libbpf进行用户态的加载;开发ebpf程序时需要编译所需要的内核头文件,在生产环境中是比较危险的,因此对于支持BTF(一种转为ebpf设计的elf文件格式)的系统内核中可以使用bpftool导出vmlinux.h之后导入开发(vmlinux中有BTF的文件相关宏定义与信息)
BPF CO-RE 需要下列组件之间的紧密合作:
BTF 类型信息:用于获取内核、BPF 程序类型及 BPF 代码的关键信息, 这也是下面其他部分的基础;
编译器(clang):给 BPF C 代码提供了表达能力和记录重定位(relocation)信息的能力;
BPF loader (libbpf):将内核的 BTF 与 BPF 程序联系起来, 将编译之后的 BPF 代码适配到目标机器的特定内核;(等于做了类似于加载binary文件中进行重定位的工作,把BTF程序进行重定位加载)
内核:虽然对 BPF CO-RE 完全不感知,但提供了一些 BPF 高级特性,使某些高级场景成为可能。
以上几部分相结合,提供了一种开发可移植 BPF 程序的史无前例的能力:这个开发 过程不仅方便(ease),而且具备很强的适配性(adaptability)和表达能力(expressivity)。 在此之前,实现同样的可移植效果只能通过 BCC 在运行时编译 BPF C 程序,而前面也分析了, BCC 开销非常高。
本来想把这个python的bcc改成gobpf加载的,但是发现好像不识别这些宏
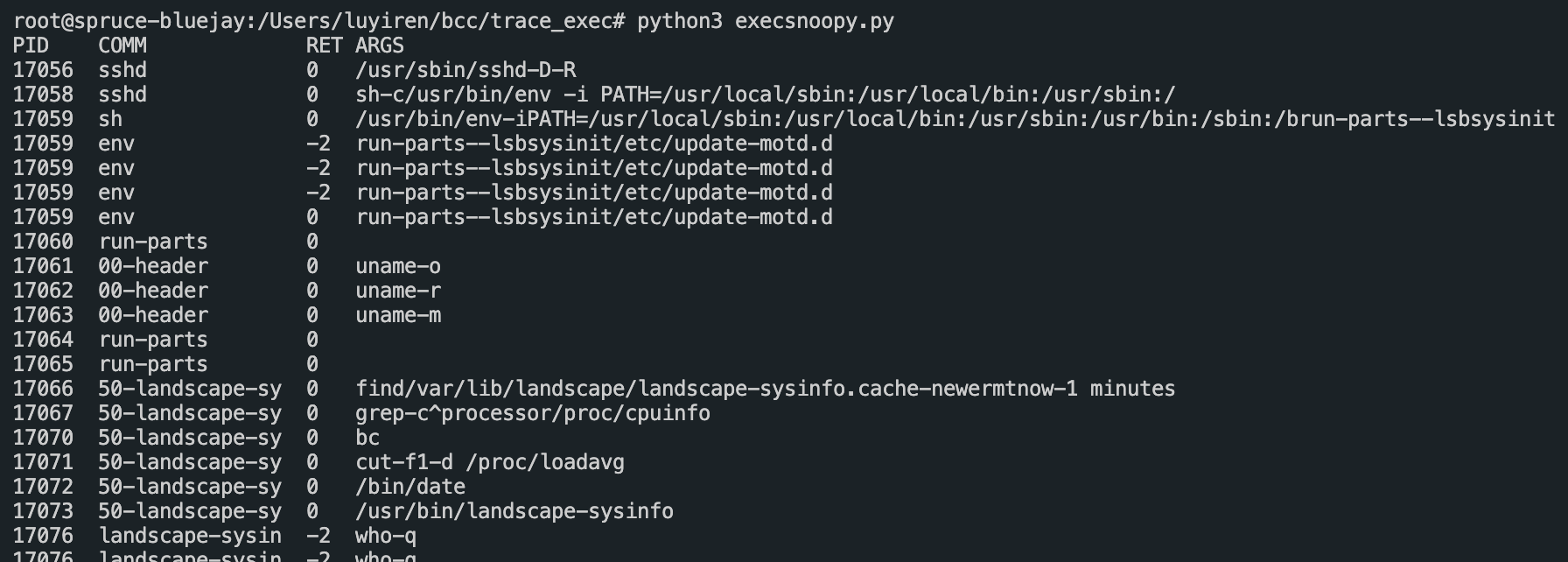
2.13
- Leetcode 每日一题, 滑动窗口
- ebpf:现阶段在成熟产品中用来加载、管理ebpf及其map一般都借用了cilium中的方案,因此这个肯定需要学习一下;kprobe用于跟踪内核事件,uprobe用于跟踪用户事件,uretprobe可以用于跟踪函数返回值,内核事件的挂载点在内核符号中已经全部给出,用户事件的挂载点需要借助入dwarf调试信息,比如在《go与ebpf的超能力组合》中一开始演示的使用bpftrace跟踪golang httpserver中的web请求就是借用了golang的符号信息.
- 编译型语言应用程序的跟踪与内核的跟踪是类似的,只不过是把跟踪类型从 kprobe 换成了 uprobe 或者 USDT(USDT 的例子我会在接下来的内容中讲到)。不同的地方在于符号信息:应用程序的符号信息可以存放在 ELF 二进制文件中,也可以以单独文件的形式,放到调试文件中;而内核的符号信息除了可以存放到内核二进制文件中之外,还会以 /proc/kallsyms 和 /sys/kernel/debug 等形式暴露到用户空间。
- 复习了数据相关知识,
2.24
- 启东人才引进报名成功,昨天预答辩也通过了,短时间内应该又可以休息下了
- LeetCode 每日一题
内核网络协议栈与对应的ebpf跟踪点(Kprobe,uprobe,USDT)
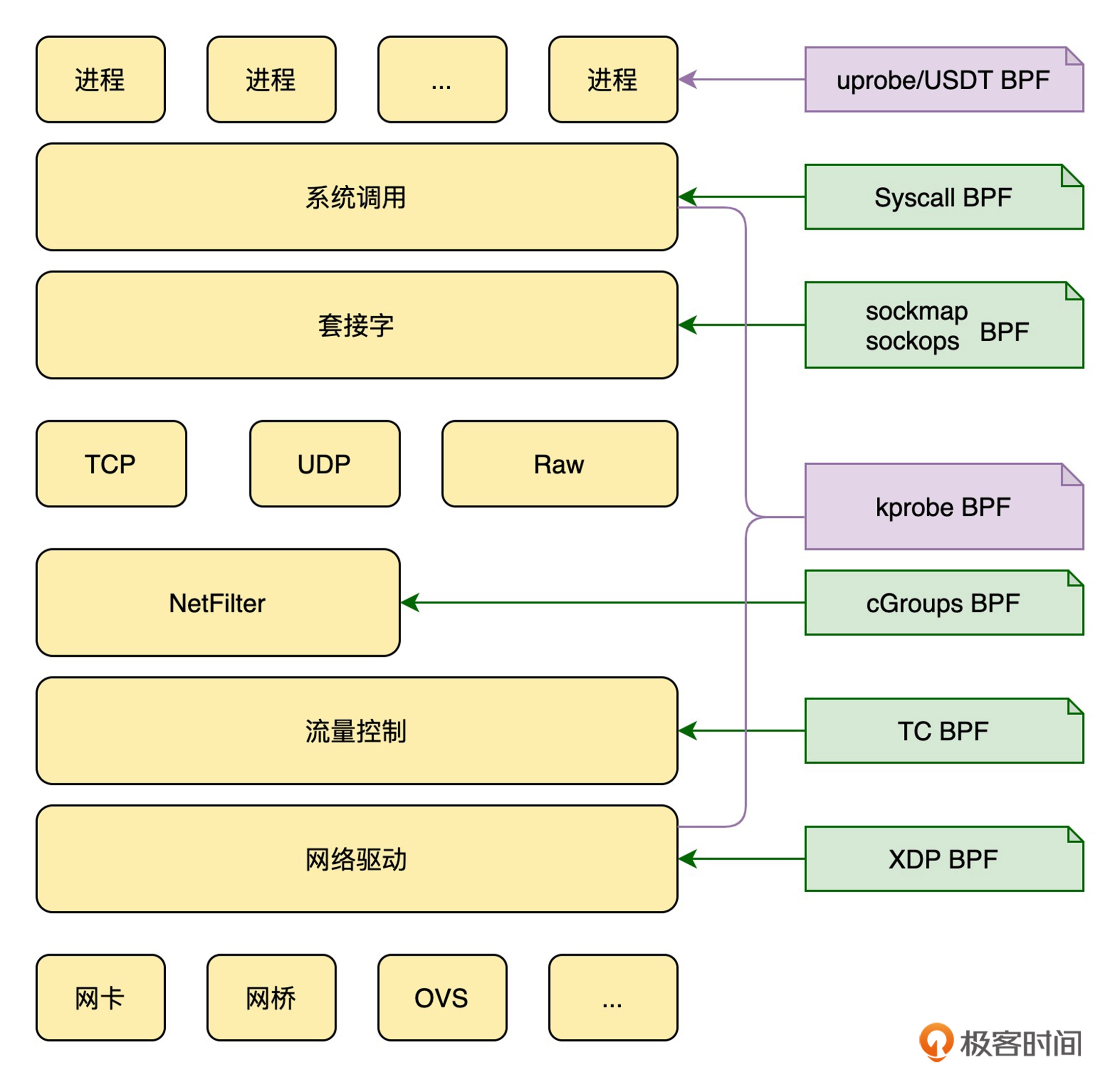
跟随实验复现的时候,我发现我的
kprobe中并没有kfree_skb,因此导出了一下相关的跟踪点,发现是在tracepoint里,kprobe中有一个kfree_skb,我猜测是更深一层次的调用,去linux源码里看一下,果然不出所料,kfree_skb中调用了kfree_skb_reason,kfre_skb_reason中则最终调用了kfree_skb,其实这两个地方跟踪都可以,参数类型都是skb_buffer,所以其实是无所谓的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* kfree_skb_reason - free an sk_buff with special reason
* @skb: buffer to free
* @reason: reason why this skb is dropped
*
* Drop a reference to the buffer and free it if the usage count has
* hit zero. Meanwhile, pass the drop reason to 'kfree_skb'
* tracepoint.
*/
void __fix_address
kfree_skb_reason(struct sk_buff *skb, enum skb_drop_reason reason)
{
if (unlikely(!skb_unref(skb)))
return;
DEBUG_NET_WARN_ON_ONCE(reason <= 0 || reason >= SKB_DROP_REASON_MAX);
if (reason == SKB_CONSUMED)
trace_consume_skb(skb);
else
trace_kfree_skb(skb, __builtin_return_address(0), reason);
__kfree_skb(skb);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28root@spruce-bluejay:/Users/luyiren/hello-near# sudo bpftrace -l "*kfree_skb*"
kfunc:__dev_kfree_skb_any
kfunc:__dev_kfree_skb_irq
kfunc:__kfree_skb
kfunc:__kfree_skb_defer
kfunc:__traceiter_kfree_skb
kfunc:kfree_skb_list
kfunc:kfree_skb_partial
kfunc:kfree_skb_reason
kfunc:kfree_skbmem
kfunc:net_dm_packet_trace_kfree_skb_hit
kfunc:rtnl_kfree_skbs
kfunc:trace_kfree_skb_hit
kprobe:__dev_kfree_skb_any
kprobe:__dev_kfree_skb_irq
kprobe:__kfree_skb
kprobe:__kfree_skb_defer
kprobe:__traceiter_kfree_skb
kprobe:kfree_skb_list
kprobe:kfree_skb_partial
kprobe:kfree_skb_reason
kprobe:kfree_skbmem
kprobe:net_dm_packet_trace_kfree_skb_hit
kprobe:rtnl_kfree_skbs
kprobe:trace_kfree_skb_hit
tracepoint:skb:kfree_skb
________________________________
root@spruce-bluejay:/Users/luyiren/hello-near# sudo bpftrace -e 'tracepoint:skb:kfree_skb /comm=="curl"/ {printf("kstack: %s\n", kstack);}'
2.25
- LeetCode每日一题,问题转化很重要
- ebpf在安全上的应用,对应的跟踪点
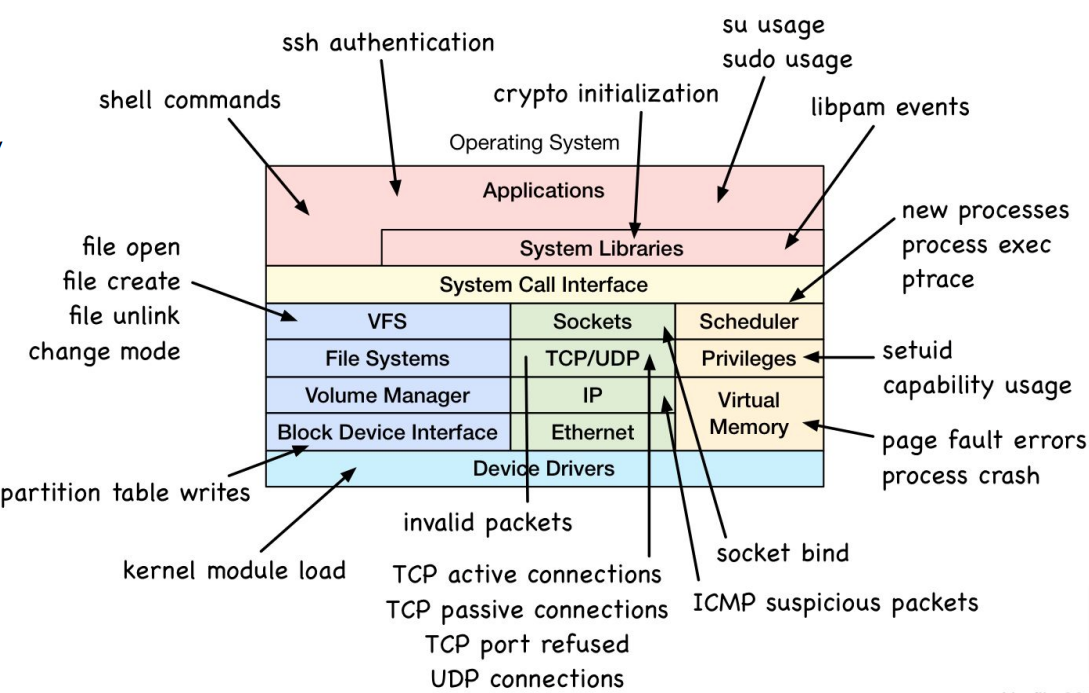
- 感觉讲的还是很浅啊,如果只是简单的用ebpf对系统调用进行监控也太简单了,这部分想要深入得看一下falco这个项目,这个项目是lsm+ebpf的,这部分开了新坑,文章在博客
2.26
- LeetCode每日一题
- 写了个小demo,借助bcc区分来自于不同container(也就是不同namespace)的系统调用
